
I published this poll on Twitter last week:
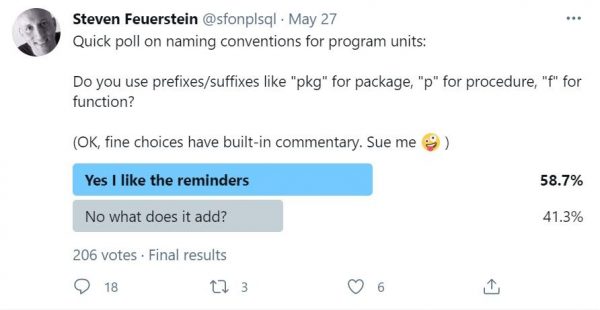
I was surprised at the results. So I thought I’d talk more about it on this week’s Feuertip.
To lay it out more generally, I was asking if, when you create a PL/SQL program unit, you include the type of program in its name. So, for example, a package that sends emails might be named mail_pkg or pkg_mail. A function that returns who the last email was sent to might be named f_last_received_by or (since we no longer have to worry about the lengths of names) function_last_received_by.
OK, fine, maybe not that last one. But why not? What’s the difference, besides the length? Why not create a package like this:
create or replace package package_mail is procedure procedure_send (...); function function_last_received_by return date; end; /
We could also follow a similar convention for local variables, constants, nested blocks, as in:
declare
constant_right_now constant date := sysdate;
local_variable_last_date date;
begin
local_variable_last_date :=
package_mail.function_last_received_by;
<<nested_block>>
declare
nested_block_local_variable_yesterday date :=
trunc (sysdate) - 1;
begin
if local_variable_last_date < constant_right_now - 10
or
nested_block.nested_block_local_variable_yesterday
< constant_right_now - 5 then package_mail.procedure_send ( parameter_to_email => 'steven@steven.steven');
end if;
end;
end;
Hmmm. No, I don’t think so. But why? These are logically equivalent:
f_last_received_by function_last_received_by
And we – the software developers of the world – are supposed to be practitioners and promoters of logic as a way to organize the world and achieve great things.
Why would a developer want to “tag” a program’s name with the type of program it is?
Apparently, to remind them of what that program is, and therefore how to use it, or how (I guess) to more easily read the code.
Certainly, it is true that in the following block of code “mystuff” could be a schema name and “do_it” a schema-level procedure. Or it could be a call to a packaged procedure.
begin mystuff.do_it; end;
But this way there is no ambiguity:
begin mystuff_package.do_it_procedure; end;
or as we are more likely to see:
begin mystuff_pkg.p_do_it; end;
But is that enough of a justification for such a convention?
Perhaps the best way to answer that question is to answer another: what’s the point of having naming conventions like these? It seems to me that there is really just one answer: to make one’s code more readable, and therefore easier to debug and maintain.
Also, remember that code consists of executable statements and comments. Generally, it is good to include comments explaining why you are doing something (the intention of the code) and not what you are doing. So when it comes to naming conventions and readability, the emphasis should be on making more clear the “what” of the code.
But it also seems to me that an assumption one should make before deciding on naming conventions is that a person reading the code has a solid working knowledge of that programming language.
I think this is reasonable. If not, you’d also have to agree that we should include voluminous comments explaining how language features used in the code work (“/* this is a collection. Collections are arrays. This is more specifically a string-indexed associative array. */”). No way we are doing that.
OK, so back to how we can use naming conventions to give information about the “what” of the code, and when that should not be necessary.
Let’s start with variables and constants. One could argue, and I am sure it is done, that you should not distinguish between these. Name them all the same way. I, on the other hand, find it useful to see at a glance that an identifier is a constant and not a variable. That has an impact on the kind of code I write. In addition, I find it helpful to understand the scope of the variable or constant. Is it defined in the specific procedure I am looking at? Is it defined at the package level?
Which is why I and many others follow conventions like this:
create or replace package body email_mgr
is
gc_today constant date := trunc (sysdate);
g_last_sent_on date := sysdate;
procedure send
is
lc_noreply constant varchar2(100) := 'noreply@emailserver.com';
l_send_from varchar2(1000) := lc_noreply;
begin
...
end;
end;
Following this line of thought, I also find it extremely helpful to know if I am looking at a parameter and not a variable or constant. Prior to joining Insum, the naming convention I followed for parameter were to include the mode of the parameter in the name as in:
procedure send (to_email_in in varchar2, email_id_out out integer)
There are a couple of potential issues with this approach: (1) for in out parameters, that’s a lot of typing (as in: email_id_in_out), and (2) they are words, so they can cause confusion depending upon the name of the parameter (example: sent_out_on_out out date).
So, OK, I made no fuss over transitioning to the Insum (inherited from Trivadis) naming convention of simply using a “p_” prefix, as in:
procedure send (p_to_email in varchar2, p_email_id out integer)
After all, the compiler will tell me if I try to use the parameter inappropriately, right? Well, at least some of the time, anyway (PL/SQL lets me read the values of out parameters!).
So we should then do the same thing for procedures and functions, right? Use “p_” in front of a procedure and “f_” in front of a function, right?
Wrong (I say).
And the reason takes us back to that assumption I mentioned earlier: ” a person reading the code has a solid working knowledge of that programming language.”
Procedures and functions look very different when invoked. A procedure invocation is an executable statement, in and of itself. A function is invoked as part of an expression within an executable statement.
We do not – we should not – need a naming convention to distinguish between the two. It is – it should be – apparent to anyone looking at the code.
Another reason I think that prefixes/suffixes for procedures and functions should not be needed is that the names of these two types of subprograms should be clearly different, in such a way as to tell you if it is a procedure or function.
The name of a procedure describes what the procedure does. The name of a function describes what the function returns.
Let’s put it all together. Here’s a piece of code that uses prefixes in the name and also doesn’t follow my advice about the structure of the subprogram names:
begin
if email_pkg.f_get_email_address_for_user (p_user_id => :p400_user_id)
= 'sfeuerstein@insum.talan.com'
then
email_pkg.p_email (
p_user_id =>:p400_user_id,
p_subject => 'You need to work on your SQL skills!');
end if;
end;
Could anyone seriously wonder whether f_get_user_email_address is a function or procedure? I sure hope not – even without the prefix and the “get” (which I propose should never be included in a function name). Similarly, is anyone thinking that p_email might be a function? I think not. Probably, instead, they are wondering “What does that procedure do?” – because the name does not tell us.
But how about this version?
begin
if email_pkg.email_address_for_user (p_user_id => :p400_user_id)
= 'sfeuerstein@insum.talan.com'
then
email_pkg.send_email (
p_user_id =>:p400_user_id,
p_subject => 'You need to work on your SQL skills!');
end if;
end;
Now the code tells its story rather smoothly:
“If the email address for this user is Steven’s, then send him an email.”
So that’s my (strong) feeling about naming conventions for subprogram: do not include a reference to the type of unit. That should be clear in the context, and if it’s not, you have other problems, such as unfamiliarity with PL/SQL or that you routinely prefix the program unit with the schema name in your code. Sometimes this might be justified, but mostly it’s a disaster waiting to unfold.
Ok, but what about package names? This is interesting because a package is a container for things to do stuff (return values, execute code, etc.). A package doesn’t “do” anything in and of itself. Consequently, many of us fall back on “_pkg”, as in “email_pkg”, just like I typed above.
I don’t like that (big surprise).
Generally, a package “covers” a certain area of functionality or a business entity. For example, I might have a package to consolidate all email-related activity. And I might have another package that contains all the business logic and data APIs needed to manage employees.
So my fallback naming convention for packages is to attach a suffix of “_mgr” to the functionality or entity name, as in: mail_mgr and employee_mgr. What do you think of this? What convention do you follow for packages?
Finally, what about tables, views, and materialized views? Should naming conventions be employed to distinguish these, like the following?
employees employees_public_info_v employees_history_mv
I have used such conventions in the past. But I remain unconvinced. The way they are used in our code is the same. The only advantage I can see to adding these suffixes is that we are reminded of how they were created when looking at those names in the code. But why should that matter? And if I need to see what is “under” the name, I can just use SQL Developer or another “smart-about-the-database” editor to tell me.
“But wait!” you might be thinking, “If Steven opts to rely on a database-smart editor for these database objects, why not also for variables vs. constants and procedures vs. functions?”
Fair point. And if you can find or are already using an editor which is that smart, perhaps you can ignore all such considerations, leave off prefixes and suffixes entirely, and let the editor show you the way.
But remember: other people working with your code might not have access to a similar tool, and thus will be at a disadvantage. Which means, by the way, that I do not think that SQL Developer is quite that smart yet.
Well, I hope this meandering post gave you something to think about. Love to read your comments and hear about what works best for you and why!
